Spark RSR: deals vs measurements
Current status
At the moment, Spark calculates RSR at the measurement (retrieval request) granularity.
Consider the following imaginary measurements for a single SP:
| Deal (PayloadCID) | IndexerResult | RetrievalResult | Evaluation |
|---|---|---|---|
bafyone | OK | OK | OK |
bafyone | OK | OK | OK |
bafyone | OK | ERROR_502 | MINORITY_RESULT |
bafyone | ERROR_500 | IPNI_ERROR_500 | MINORITY_RESULT |
Qm1234 | ERROR_404 | IPNI_ERROR_404 | OK |
Qm1234 | ERROR_404 | IPNI_ERROR_404 | OK |
Qm1234 | ERROR_404 | IPNI_ERROR_404 | OK |
Qm1234 | ERROR_500 | ERROR_502 | MINORITY_RESULT |
Before the recent change that introduced “committees and majorities” (see roadmap#59), the measurements with MINORITY_RESULT evaluation were evaluated as OK. We would get the following RSR:
- Total accepted measurements: 8
- Successfull retrievals: 2
- RSR: 25%
With the committees & majorities in place, we get the following RSR:
- Total accepted measurements: 5
- Successfull retrievals: 2
- RSR: 40%
Initial Proposal
I am arguing that we should provide two RSR values:
- % of deals that are retrievable based on what the majority reports.
- % of retrieval requests that were successful. A “retrieval request” means a request to the SP. The are no retrieval requests for deals that are not advertised to IPNI.
Using the example data above, we would get the following results:
- Deal Retrievability Score (DRS)
- Total deals tested: 2
- Deals where majority agrees on retrievability: 1
- Score: 50%
- Retrieval Request Success Rate (RRSR):
- Retrieval requests performed: 3 (the first three rows in the table)
- Successful retrievals: 2
- Score: 66%
Important: to calculate this score, we need to look at measurements that were considered to be valid measurements but that we later rejected because they are in minority.
A storage provider that serves retrievals well should score:
- 100% of deals are retrievable
- Majority of retrieval requests are handled. We don’t expect SPs to achieve 100% score, because some requests can fail for reasons outside of SPs control, typically client-side networking issues.
Note that it’s possible to have a low Deal-based score and a high Request-based score, therefore it’s crucial to always look at DRS first and treat RRSR as a secondary metric only.
- Let’s say a SP stores 100 deals, serves retrievals for one deal only, and serves these retrievals very well.
- In such case, DRS will be 1% and RRSR will be >99.9%.
Implementation Plan
This is no longer relevant if we decide to implement the alternative presented below.
- Deprecate the current
retrieval_statstable that’s powering REST API endpoints related to retrieval stats.Here is the current schema of
retrieval_statstable: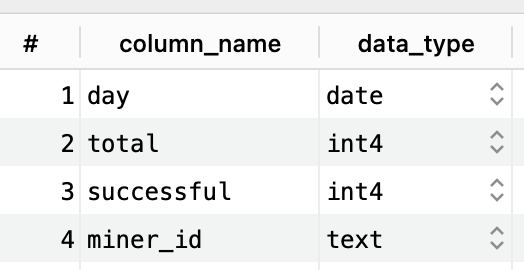
- Add the following columns to
daily_dealstable, so that it can serve as a replacement forretrieval_stats:miner_id
requests_total
requests_successful
Backfill the request counts from
retrieval_stats.Caveat: the data in
retrieval_statswas counting all retrieval attempts, including those where the deal was not advertised to IPNI. The RRSR from this old data will NOT be comparable with RRSR calculated using the new mechanism.Here is the current schema of
daily_dealstable: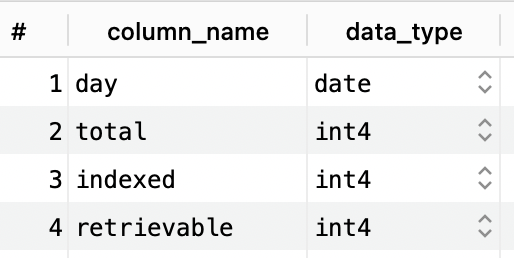
- Modify the code in spark-evaluate populating
daily_dealsto set values for the new columns.
- Rework all spark-stats endpoints reading from
retrieval_statsto usedaily_dealsinstead.
- Drop the table
retrieval_stats.
- Deprecate the current
Alternatives
No continuity from RSR to RRSR
Because RRSR is sligthly different from RSR, instead of preserving continuity of the daily score reports, it may be better to create new REST API endpoints for this new score, and remove the old API endpoints showing RSR.
- This removes any confusion. Whoever is consuming RSR needs to decide whether they want to consume DRS or RRSR going forward.
- If we remove the RSR endpoints, then anybody consuming the data will very quickly discover the change. This is great if there are people using Spark Stats we don’t know about.
- However, this also means we are creating urgent work for everybody using RSR endpoints. (This includes us, we will need to rework all dashboards.)
Alternatively, we can keep the old RSR endpoints and deprecate them:
- Remove the endpoints from the docs
- Work with the known users of these endpoints on their migration plan
- Downside: we have to maintain more code and pay for extra storage to support these deprecated endpoints.
No score at request level granularity
Considering the nuances for RRSR and how it is similar but also different from the current RSR, it may be better to not calculate/expose any scores based on individual retrieval requests (measurements).
At high level, I am proposing to stop looking at individual measurements and look at deal-level data only.
The following argument can be make to support this option: We cannot trust individual measurements, only the “honest majority” gives us confidence that we are producing correct data (observations).
- We form committees at the deal level. Then we assume that the majority of nodes is honest and does not have any networking issues on the route between them and the SP. Based on that assumption, we trust the majority result to be correct. In other words, Spark answers the question “does the majority of the network agree that this deal can be retrieved?”
- We don’t have any guarantees about individual measurements. A measurement saying the retrieval request failed could be caused by many different reasons which we cannot determine on our side - client-side networking issues, Great China Firewall, rate-limiting implemented by SP, adversay client faking the data. Only one of these four cases is a legitimate request failure that should reduce SP’s score. All other cases should not affect SP’s score. It would be unfair to them, because those things are outside of their control. (We can debate whether it’s reasonable to require SPs to be able to handle clients on both sides of the Great China Firewall.)
If we agree on this approach, then we need to decide how to implement the change in the REST API:
- Rework existing endpoints to start returning deal-based scores instead of measurement-based scores. I think this will likely create too much confusion.
- Add new endpoints for deal-based score. Decide whether we want to drop or deprecate the existing measurement-based endpoints - see the discussion in about the ramifications.
Ramifications:
- We started collecting deal-based scores on Jun 12. There is no way how to backfill deal-based scores from measurement-based scores.
- We didn’t have committees & majorities back then, therefore I implemented the rule that a a deal is indexed/retrievable if at least one (accepted/honest) measurement indicates that. Obviously, that’s very easy to cheat, therefore I don’t trust this data too much.
Open questions
- I expect that the new RRSR will be different from the current RSR. How to explain this change in the Grafana dashboards?
- Note: if we drop RSR & RRSR in favour of deal-based score, then this question becomes different - how do we want to handle the fact that we don’t have any deal-based scores before June 12th and the scores calculated before Aug 28th may be fraudulent?
- Whom do we need to notify about this change? (Who is consuming this data?)
- We will need to explain them the nuances, like the difference between DRS and RRSR.
- They will need to decide which metric they want to consume going forward.
- I think that FIL+ should use DRS for compliance checking, because RRSR can be affected by the internet network conditions of the checker nodes (Stations).
- How & where to communicate DRS and the change
- A blog post explaining the changes and the rationale behind them
- Publicise the blog post (and the change) in social media (Twitter, Telegram, Slack, etc.)
- Is there any documentation we need to update?